
Methods for Automated Hyperparameter Optimization
The three main algorithms used in automated hyperparameter optimization are
- Grid Search
The main difference between the three algorithms is how they select the set of hyperparameter values to test next. But they are also different in how you define the search space (fixed values vs. value ranges) and how you specify the number of runs (implicit vs. explicit).
This section will explore these differences and their advantages and disadvantages.
I will use W&B Sweeps to optimize the hyperparameters epochs and learning_rate in the following. For more details, you can check out my related Kaggle Notebook and W&B project.
Grid Search
Grid search is a hyperparameter tuning technique that evaluates all possible hyperparameter combinations in a specified grid (Cartesian product). It is a brute-force approach recommended only for ML models with few hyperparameters.
Inputs
- A set of hyperparameters you want to optimize
- A discretized search space for each hyperparameter either as specific values
- A performance metric to optimize
- (Implicit number of runs: Because the search space is a fixed set of values, you don’t have to specify the number of experiments to run)
(The differences between random search and Bayesian optimization are highlighted in bold above.)
A popular way to implement grid search in Python is to use GridSearchCV from the scikit learn library. Alternatively, as shown below, you can set up a grid search for hyperparameter tuning with W&B:

Steps
Step 1: The grid search algorithm selects a set of hyperparameter values to evaluate by creating a grid (cartesian product) of all possible hyperparameter combinations of the specified hyperparameter values. Then it simply iterates over the grid. This approach is an exhaustive search or brute force approach.
Below, you can see the resulting grid for our example.
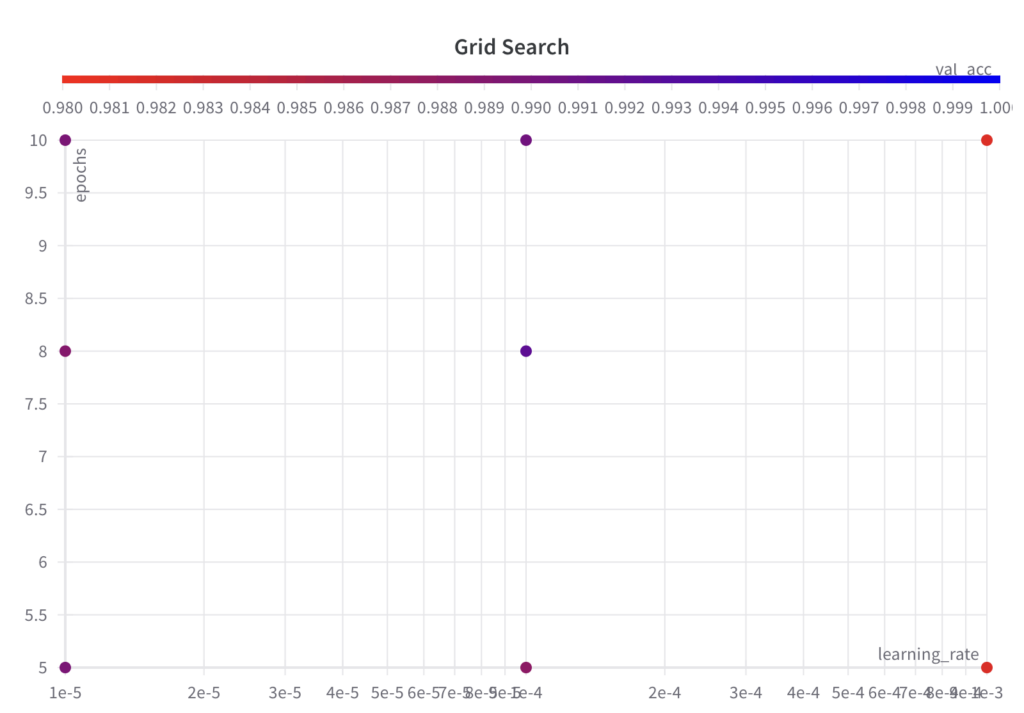
Step 2: Run an ML experiment for the selected set of hyperparameters and their values, and evaluate and log its performance metric.
Step 3: Repeat for the specified number of trial runs or until you are happy with the model’s performance
Output
As with all automated hyperparameter optimization algorithms, Grid Search returns the experiment with the best performance metric and the respective hyperparameter values.
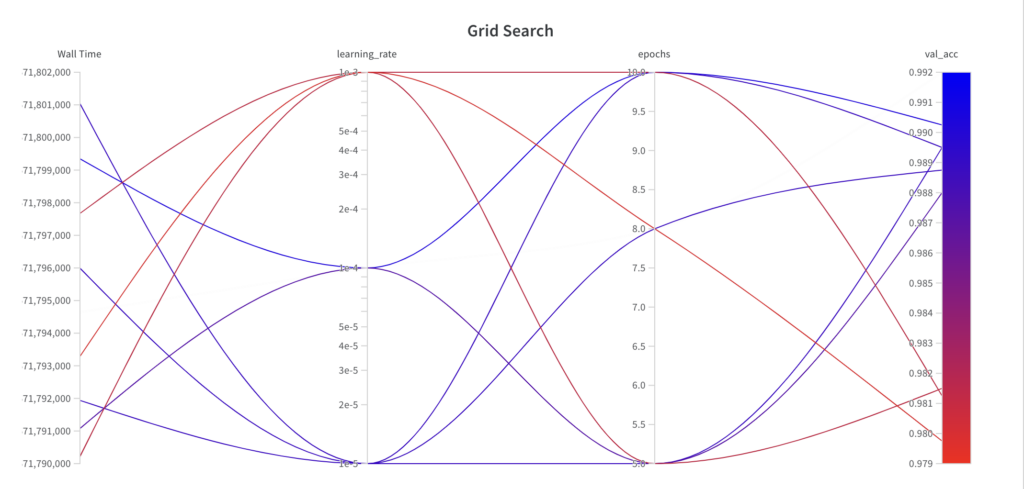
Below you can see at which time the hyperparameter optimization algorithm chose which parameters and the resulting performance. You can make the following observations:
- The grid search algorithm iterates over the grid of hyperparameter sets as specified.
- Since grid search is an uninformed search algorithm, the resulting performance doesn’t show a trend over the runs.
- The best val_acc score is 0.9902
Advantages
- Simple to implement
- Can be parallelized: because the hyperparameter sets can be evaluated independently
Disadvantages
- Not suitable for models with many hyperparameters: this is largely because the computational cost grows exponentially with the number of hyperparameters
- Uninformed search because knowledge from previous experiments is not leveraged. You may want to run the grid search algorithm several times with a fine-tuned search space to achieve good results.
Unless you have three or fewer hyperparameters to tune, it is generally recommended to avoid grid search.
Random Search
Random search is a hyperparameter tuning technique that randomly samples values from a specified search space. It is more effective than grid search for ML models with many hyperparameters where only a few affect the model’s performance [1].
Inputs
- A set of hyperparameters you want to optimize
- A continuous search space for each hyperparameter as a value range
- A performance metric to optimize
- Explicit number of runs: Because the search space is continuous, you must manually stop the search or define a maximum number of runs.
The differences to grid search are highlighted in bold above.
A popular way to implement random search in Python is to use RandomizedSearchCV from the scikit learn library. Alternatively, as shown below, you can set up a random search for hyperparameter tuning with W&B.

Steps
Step 1: The random search algorithm selects a set of hyperparameters to evaluate by randomly sampling hyperparameter values from the specified search space for each iteration for the number of specified iterations.
Below, you can see that the sampled sets of hyperparameter values do not follow a grid like in the grid search algorithm:
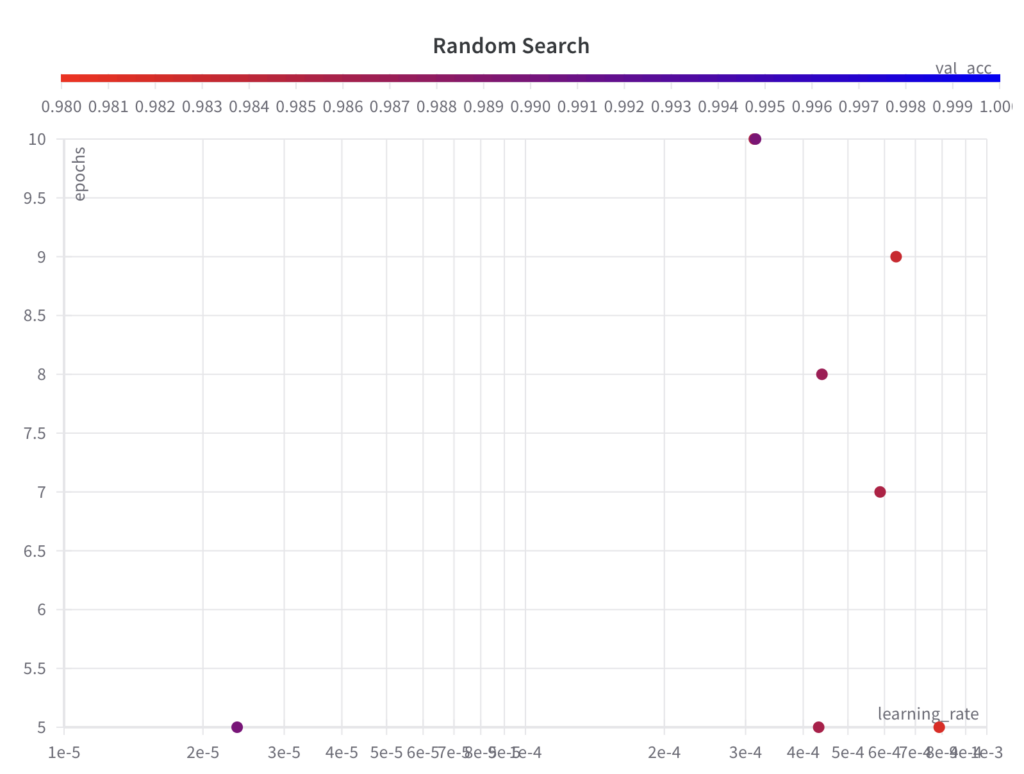
Step 2: Run an ML experiment for the selected set of hyperparameters and their values, and evaluate and log its performance metric.
Step 3: Repeat for the specified number of trial runs.
Output
As with all automated hyperparameter optimization algorithms, Random Search returns the experiment with the best performance metric and the respective hyperparameter values.
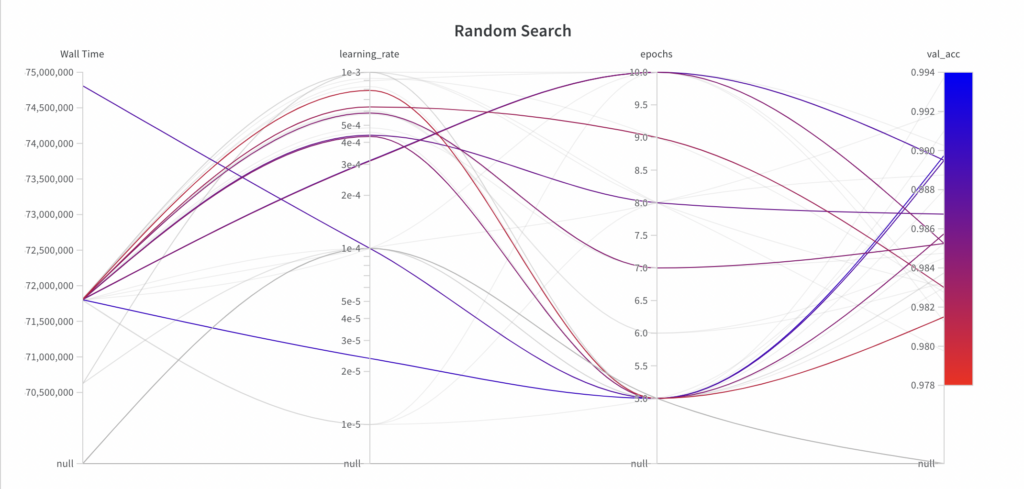
Below you can see at which time the hyperparameter optimization algorithm chose which parameters and the resulting performance. You can make the following observations:
- While random search samples values from the full search space for the hyperparameter epochs, it doesn’t explore the full search space for the hyperparameter learning_rate within the first few experiments.
- Since random search is an uninformed search algorithm, the resulting performance doesn’t show a trend over the runs.
- The best val_acc score is 0.9868, which is worse than the best val_acc score achieved with grid search (0.9902). The main reason for this is assumed to be the fact that the learning_rate has a large impact on the model’s performance, which the algorithm failed to sample properly in this example.
Advantages
- Simple to implement
- Can be parallelized: because the hyperparameter sets can be evaluated independently
- Suitable for models with many hyperparameters: Random search is guaranteed to be more effective than grid search for models with many hyperparameters and only a small number of hyperparameters that affect the model’s performance [1]
Disadvantages
- Uninformed search because knowledge from previous experiments is not leveraged. You may want to run the random search algorithm several times with a fine-tuned search space to achieve good results.
Bayesian Optimization
Bayesian optimization is a hyperparameter tuning technique that uses a surrogate function to determine the next set of hyperparameters to evaluate. In contrast to grid search and random search, Bayesian optimization is an informed search method.
Inputs
- A set of hyperparameters you want to optimize
- A continuous search space for each hyperparameter as a value range
- A performance metric to optimize
- Explicit number of runs: Because the search space is continuous, you must manually stop the search or define a maximum number of runs.
The differences in grid search are highlighted in bold above.
A popular way to implement Bayesian optimization in Python is to use BayesianOptimization from the bayes_opt library. Alternatively, as shown below, you can set up Bayesian optimization for hyperparameter tuning with W&B.

Steps
- Step 1: Build a probabilistic model of the objective function. This probabilistic model is called a surrogate function. The surrogate function comes from a Gaussian process [2] and estimates your ML model’s performance for different sets of hyperparameters.
- Step 2: The next set of hyperparameters is chosen based on what the surrogate function expects to achieve the best performance for the specified search space.
Below, you can see that the sampled sets of hyperparameter values do not follow a grid like in the grid search algorithm.
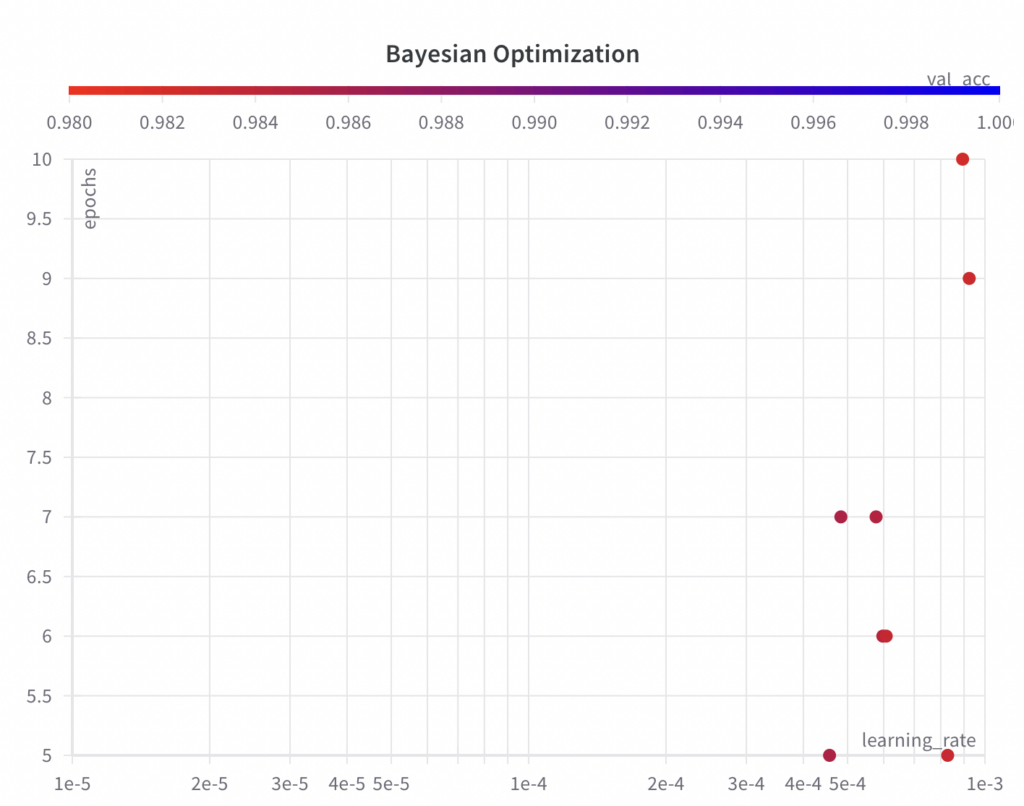
- Step 3: Run an ML experiment for the selected set of hyperparameters and their values, and evaluate and log its performance metric.
- Step 4: After the experiment, the surrogate function is updated with the last experiment’s results.
- Step 5: Repeat steps 2 – 4 for the specified number of trial runs.
Output
As with all automated hyperparameter optimization algorithms, Bayesian Optimization returns the experiment with the best performance metric and the respective hyperparameter values.
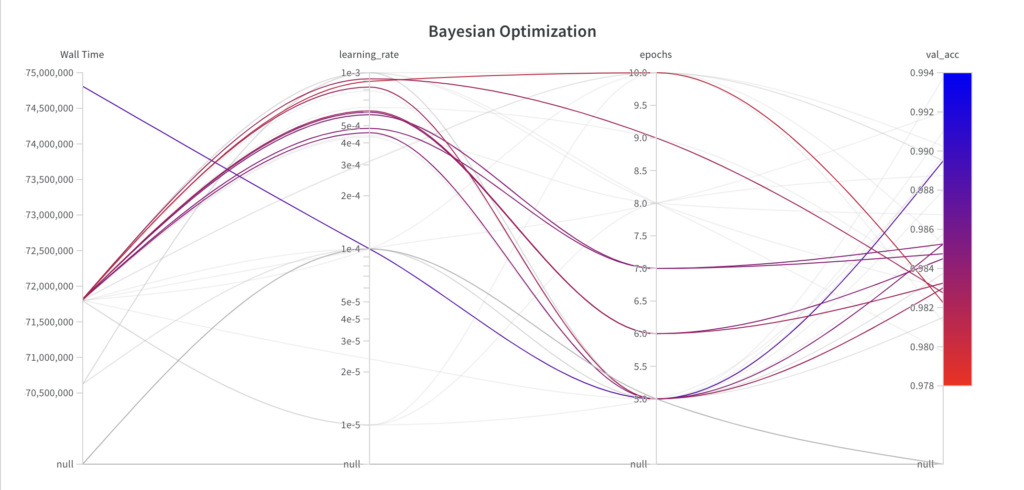
Below you can see at which time, the hyperparameter optimization algorithm chose which parameters and the resulting performance. You can make the following observations:
- While the Bayesian optimization algorithm samples values from the full search space for the hyperparameter epochs, it doesn’t explore the full search space for the hyperparameter learning_rate within the first few experiments.
- Since the Bayesian optimization algorithm is an informed search algorithm, the resulting performance shows improvements over the runs.
- The best val_acc score is 0.9852, which is worse than the best val_acc score achieved with grid search (0.9902) and random search (0.9868). The main reason for this is assumed to be the fact that the learning_rate has a large impact on the model’s performance, which the algorithm failed to sample properly in this example. However, you can see that the algorithm has already begun to decrease the learning_rate to achieve better results. If given more runs, the Bayesian optimization algorithm could potentially lead to hyperparameters which result in a better performance.
Advantages
- Suitable for models with many hyperparameters
- Informed search: Takes advantage of knowledge from previous experiments and thus can converge faster to good hyperparameter values
Disadvantages
- Difficult to implement
- Can’t be parallelized because the next set of hyperparameters to be evaluated depends on the previous experiment’s results